
CHAPITRE I: Les bases de la clause MODEL
La clause MODEL d’Oracle est utilisée pour générer des valeurs sous condition. Elle peut générer des valeur à partir de rien ou à partir de cellules existantes dans la table ou déjà calculées avec cette même clause. Cela en fait un outil de calcul puissant qui bien utilisé rend obsolète votre tableur préféré.
Premier exemple de génération.
Je veux générer de toutes pièces un tableau (une table) qui va me servir à calculer phi (ou nombre d’or).
- Je sais que la valeur théorique de phi est de (1+√5)/2.
- Je sais aussi que la suite de Fibonacci permet d’approcher ce nombre en divisant un de ses termes par le précédent (phi ≅ fibo(n)/fibo(n-1))
- Je suis curieux, je veux aussi calculer l’écart entre le rapport fibo(n)/fibo(n-1) et la valeur théorique
En utilisant un tableur, en l’occurrence Excel
Avec Excel je calculerait ma colonne fibo en initalisant deux lignes à 1 et à partir de la troisième je lui dirais avec une formule que la valeur courante est égale à la somme des deux lignes précéndes dans la même colonne ce qui s’écrit en utilisatant la norme L1C1 (ou R1C1 pour la version anglaise de bidule) =L(-1)C+L(-2)C.
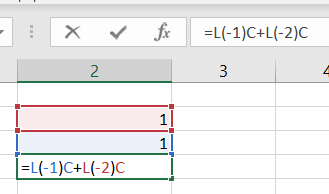
Je calculerai la valeur de phi à partir de ma colonne fibo calculée sur le même modèle ( 1 ligne initialisées à 1 et les suivantes comme le rapport de la valeur courante de la colonne fibo sur la valeur précédente de la colonne fibo. Ce qui peut s’écrire, toujours en [R|L]1C1 =LC(-1)/L(-1)C(-1).
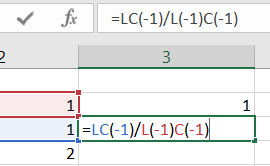
Vient ensuite la valeur théorique, qui rappelons le est de (1+√5)/2 soit pour une formule excel =(1+racine(5))/2.
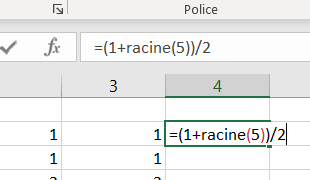
Enfin le calcul de pourcentage d’écart (ou d’erreur) entre la valeur calculée et la valeur théorique. Soit pour une formule excel [L|R]1C1 =(1-LC(-2)/LC(-1))/2.
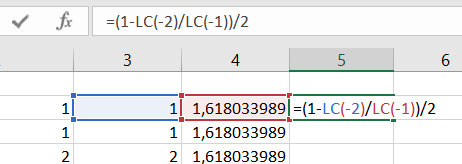
Voilà, pour peu que je déploie un peu mes formules sur 100 lignes, j’ai une jolie feuille de calcul Excel qui nous donne les 100 premières valeurs de la suite de fibonacci ainsi qu’une valeur approchée du nombre d’or que je peux comparer à sa valeur théorique.
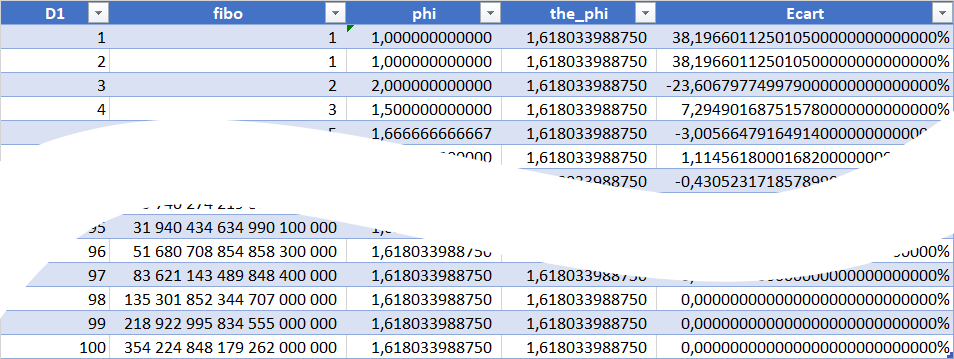
Ok … Mais avec excel je savais déjà faire, et je ne profite pas de la puissance de calcul d’Oracle.
La même chose avec Oracle et la clause MODEL
La clause MODEL d’Oracle me propose d’ajoûter des colonnes virtuelles à ma table et de leur affecter des valeurs calculées ou constantes.
Dimension
Je veux donc calculer tous les termes, du 1er au centième, d’une suite de fibonacci, m’en servir pour approcher le nombre d’or et avoir une idée de l’erreur entre deux lignes. Pour celà je vais générer une table contenant les entiers de 1 à 100 avec un bon vieux générateur CONNECT BY, comme on les aime chez Oracle:
select rownum D1 from dual connect by rownum <= 100 ;
Je vais m’appuyer sur cette colonne pour effectuer mes calculs, je vais donc préciser au modèle que cette colonne me sert de dimension
model dimension by (D1)
Mesures
Je m’appuie ensuite sur cette table, que j’appelle t pour décrire ce que je veux faire.
Comme dans Excel je vais définir mes colonnes à calculer pour lesquelles je vais donner une valeur par défaut (pas si) arbitraire. Toutes les colonnes de mesures doivent être initialisées à une valeur non nulle.
measures(1 as fibo, 1 as phi, (1+sqrt(5))/2 as the_phi, 0 as ecart)
J’affecte donc 1 à toutes les lignes de la colonne fibo et de la colonn phi, 0 à toutes les lignes de la colonne ecart et (1+√5)/2 à toutes les lignes de la valeur théorique de phi que j’ai appelée the_phi.
Règles de calcul
Je vais m’appuyer sur cette table virtuelle (100 lignes, 5 colonnes) pour expliquer à Oracle grâce à la clause rules, les règles de calcul que j’ai utilisées sur excel
Tout d’abord le calcul des éléments de la suite de fibonacci. On s’en souvient, les deux premiers éléments (les deux premières lignes en l’occurrence) valent 1 et les suivant(e)s se calculent à partir des deux lignes précédentes. Ce qui donne ces règles:
fibo[1]=1, fibo[2]=1, fibo[D1 > 2]=fibo[cv()-1]+fibo[cv()-2]
Ok … C’est abscon ? Comparons à Excel.
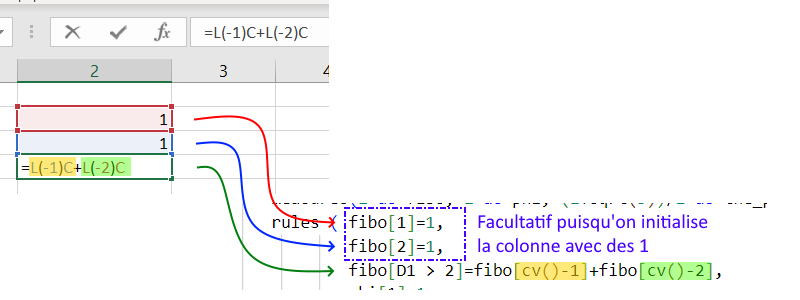
On notera la fonction cv() qui donne le numéro de ligne courant, et que j’ai ajouté les lignes fibo[1] et fibo[2] pour comparer plus facilement avec Excel mais inutilemen du fait de l’initialisation. Enfin on notera aussi quue l’on repêre la colonne par son nom
En ce qui concerne le calcul de phi, on est sur la même logique, sauf qu’on utilise une autre colonne, à savoir fibo
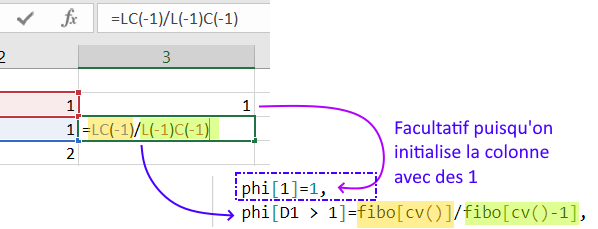
Pour le calcul des écarts on s’appuie sur la colonne phi telle que calculée et la valeur théorique créée artificiellement en colonne the_phi
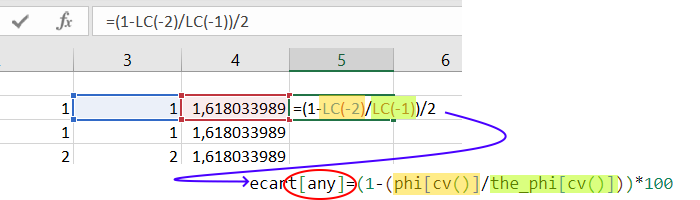
On note le pseudo index any qui veut dire, pour toutes les lignes de la colonne
Requête complète
Ce qui me donne pour un premier jet la requête suivante:
with t as ( select rownum D1 from dual connect by rownum <= 100 )
select D1
, fibo
, phi
, the_phi
, ecart
from t
model dimension by (D1)
measures(1 as fibo, 1 as phi, (1+sqrt(5))/2 as the_phi, 0 as ecart)
rules ( fibo[1]=1,
fibo[2]=1,
fibo[D1 > 2]=fibo[cv()-1]+fibo[cv()-2],
phi[1]=1,
phi[D1 > 1]=fibo[cv()]/fibo[cv()-1],
ecart[any]=(1-(phi[cv()]/the_phi[cv()]))*100
)
order by D1;
Si je fais un peu de ménage pour enlever tout ce qui ne m’est pas vraiment utile (la colonne D1, les valeurs forcées de fibo[1], fibo[2] et phi[1], j’obtiens la requête suivante.
with t as ( select rownum D1 from dual connect by rownum <= 100 )
select fibo
, phi
, the_phi
, ecart
from t
model dimension by (D1)
measures(1 as fibo, 1 as phi, (1+sqrt(5))/2 as the_phi, 0 as ecart)
rules ( fibo[D1 > 2]=fibo[cv()-1]+fibo[cv()-2],
phi[D1 > 1]=fibo[cv()]/fibo[cv()-1],
ecart[any]=(1-(phi[cv()]/the_phi[cv()]))*100
)
order by D1;
Y’a moyen de faire autrment ?
OUI! On peut utiliser un génrateur qui donne la suite de fibonacci, tout ça aussi avec des case et des lag over partition et … Si on l’écrivait ?
with t (D1, fibo, accu_f) as
(select 1, 1, 0
from dual
union all
select D1+1, fibo+accu_f, fibo
from t
where D1<=100),
u as (
select fibo
, case when D1 > 1 then fibo / lag(fibo,1) over (partition by 1 order by D1)
else 1 end phi
from t
)
select fibo
, phi
, (1+sqrt(5))/2 as the_phi
, (1-( phi/((1+sqrt(5))/2) )) * 100 ecart
from u ;
On obtient le même résultat, mais c’est moins lisible. Je suis, en effet contraint de passer par deux tables intermédiaires car les colonnes en cours de calcul ne sont pas interrogeables directement. Mais ça marche.
Mais au fait, ça donne quoi ?
Les 40 premières lignes sont les suivantes, quel que soit le code utilisé et moyennant un formattage adéquat des colonnes.
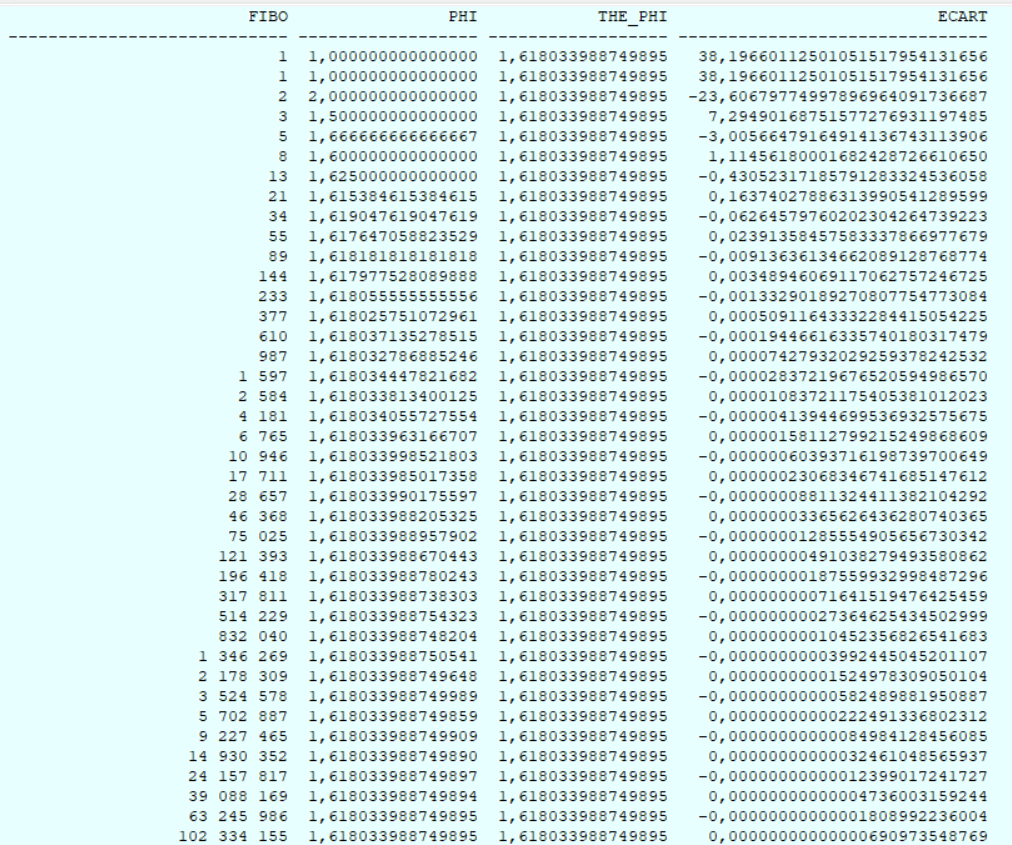
Et du point de vue de la performance ?
Clause MODEL
with t as ( select rownum D1 from dual connect by rownum <= 100 )
select fibo
, phi
, the_phi
, ecart
from t
model dimension by (D1)
measures(1 as fibo, 1 as phi, (1+sqrt(5))/2 as the_phi, null as ecart)
rules ( fibo[D1 > 2]=fibo[cv()-1]+fibo[cv()-2],
phi[D1 > 1]=fibo[cv()]/fibo[cv()-1],
ecart[any]=(1-(phi[cv()]/the_phi[cv()]))*100
)
order by D1
/
100 lignes sélectionnées.
Ecoulé : 00 :00 :00.00
Plan d'exécution
----------------------------------------------------------
Plan hash value: 1738149122
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 1 | 13 | 3 (34)| 00:00:01 |
| 2 | SQL MODEL ORDERED | | 1 | 13 | 3 (34)| 00:00:01 |
| 3 | VIEW | | 1 | 13 | 2 (0)| 00:00:01 |
| 4 | COUNT | | | | | |
|* 5 | CONNECT BY WITHOUT FILTERING| | | | | |
| 6 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(ROWNUM<=100)
Statistiques
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
6432 bytes sent via SQL*Net to client
856 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
100 rows processed
Avec un code SQL plus classique
with t (D1, fibo, accu_f) as
(select 1, 1, 0
from dual
union all
select D1+1, fibo+accu_f, fibo
from t
where D1<=100),
u as (
select fibo
, case when D1 > 1 then fibo / lag(fibo,1) over (partition by 1 order by D1)
else 1 end phi
from t
)
select fibo
, phi
, (1+sqrt(5))/2 as the_phi
, (1-( phi/((1+sqrt(5))/2) )) * 100 ecart
from u
/
100 lignes sélectionnées.
Ecoulé : 00 :00 :00.01
Plan d'exécution
----------------------------------------------------------
Plan hash value: 4009850109
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 52 | 5 (20)| 00:00:01 |
| 1 | VIEW | | 2 | 52 | 5 (20)| 00:00:01 |
| 2 | WINDOW SORT | | 2 | 52 | 5 (20)| 00:00:01 |
| 3 | VIEW | | 2 | 52 | 4 (0)| 00:00:01 |
| 4 | UNION ALL (RECURSIVE WITH) BREADTH FIRST| | | | | |
| 5 | FAST DUAL | | 1 | | 2 (0)| 00:00:01 |
|* 6 | RECURSIVE WITH PUMP | | | | | |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - filter("D1"<=100)
Statistiques
----------------------------------------------------------
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
6432 bytes sent via SQL*Net to client
866 bytes received via SQL*Net from client
8 SQL*Net roundtrips to/from client
102 sorts (memory)
0 sorts (disk)
100 rows processed
Comparaison d’efficacité
Les plans de requêtes sont différents, je m’attends à une différence de performance. Le centième de seconde d’écart entre les deux exécutions mais ce n’est pas significatif mais semble indiquer que la requête avecla clause MODEL serait meilleure. Pourtant j’ai le même nombre de consistent GETS (bien sûr d’octets envoyés et d’aller/retour SQL*Net, puisque j’ai génèré des résultats identiques). C’est dans les tris que la différence se fait, 2 pour la requête utilisant la clause MODEL, 102 avec une requête plus classique. Donc Du point de vue strict de la performance, dans ce cas, il vaut mieux privilégier la clause MODEL